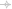
Wordseer: какие слова у Шекспира чаще всего определяют существительное «жизнь»?
Мы продолжаем рассказывать о проектах в области «цифровых гуманитарных наук», поддержанных американским Национальным гуманитарным фондом (National Endowment for the Humanities).
 |
Еще одним лауреатом стал Wordseer — сервис для анализа текстовых коллекций, разработанный на кафедре компьютерных технологий (computer science) университета Беркли (основные разработчики — Адити Муралидхаран и Марти Херст). Wordseer дает возможность поиска по корпусу текстов с учетом грамматических и синтаксических метаданных — например, в каких контекстах Шекспир использует слово «любовь» или «красота», кто из героев Шекспира чаще говорит о меланхолии — мужчины или женщины, какие прилагательные чаще всего сочетаются с существительным «меланхолия». Демовидео (по ссылке ниже) демонстрирует также возможности тезаурусного поиска (если слово “beautiful” у Шекспира встречается всего 16 раз, какими же словами герои выражают свои представления о красоте?) Полученные результаты можно визуализировать в форме “heat maps” (пиксельных диаграмм частотности) или наиболее частотных контекстных цепочек типа “X — is — fair — and — Y”.
Создатели Wordseer выбрали полное собрание сочинений Шекспира одной из четырех тестовых площадок для своего проекта (не только из любви к его творчеству, но и потому, что весь корпус текстов должен быть представлен в формате XML с правильно указанными метаданными). Здесь с помощью опции “described as” вы можете мгновенно узнать, что для слова «война» наиболее частотные определения — «гражданская» (4 раза), «кровавая», «ужасная» и «жестокая» (по 2 раза). Можно выбрать любое количество отдельных текстов, чтобы сравнить, как одни и те же слова и формы используются, например, в комедиях и трагедиях. Для любого отрывка текста можно сгенерировать список использованных в нем «грамматических паттернов» (особенно это важно для рукописных или диалектных корпусов — например, воспоминаний, записанных со слов бывших рабов-афроамериканцев).
Нет ли опасности, что студенты скоро начнут изучать Шекспира по таблицам и диаграммам частотности? Как правильно интерпретировать результаты, которые выдает система? Об этом на примере проекта Wordseer пишет Стефани Вандеуорк (Stephanie Vandewark), студентка университета Калгари. С ее выводом трудно не согласиться: чтобы получить какой-то количественный показатель, нужно заранее иметь гипотезу, которую вы хотите проверить. Даже если Wordseer или любой другой инструмент пригодится вам в качестве “serendipity machine” — генератора озарений, то без знания текста и аналитических навыков научного исследования не получится.
Возвращаясь к вопросу, вынесенному в заглавие: попробуйте ответить на него сами. Результат вас может слегка удивить.
Демовидео “Wordseer: Men and Women in Shakespeare”
Демовидео “Wordseer:
Love Is Everywhere! Shakespeare’s Tragedies And Comedies”
Демовидео “Wordseer: ‘Beautiful’ in Shakespeare”
См. также:
- Презентация Wordseer в National Endowment for the Humanities
- Рецензия Эми Эрхарт в Journal of Digital Humanities
В. С. Макаров
Vladimir Makarovon![]()